در این نوشتار قصد داریم تا شما را با نحوه ایجاد واژهنامه و فهرست اختصارات در زیپرشین با استفاده از بسته glossaries آشنا سازیم. glossaries بستهای است بسیار قدرتمند که توسط خانم Nicola Talbot با چنین هدفی نوشته شده است.

مزایا
در پاسخ به این سوال که این بسته چه مواردی را برای ما به ارمغان میآورد میتوان موارد زیر را برشمرد:
- اضافه نمودن و مرتبسازی واژهها و اختصارات تعریف شده به صورت خودکار به فهرست واژگان و اختصارات. بر طبق این ویژگی کافی است که شما واژگان و اختصارات خود را در متن در مکان دلخواه استفاده کنید. بسته glossaries به صورت خودکار واژگان را به صورت مرتب شده در فهرست واژگان و اختصارات وارد میکند.
- کنترل کامل بر روی واژگان و اختصارات تعریف شده در متن. به عنوان مثال اگر بخواهید اولین باری که از یک واژه یا اختصار در متن استفاده میکنید، معادل فارسی یا انگلیسی آن پاورقی بخورد، نیازی نیست به دنبال اولین مکان فراخوانی بگردید. بسته glossaries این کار را برای شما انجام میدهد، و علاوه بر این تمامی اقدامات لازم را بر روی واژه مورد نظر اعمال میکند.
- آسانسازی تغییرات در متن. فرض کنید که شما عبارت Ad Hoc Network را در ابتدا شبکه اقتضایی ترجمه کردید. اکنون بنا به دلیلی تصمیم گرفتید معادل فارسی شبکه موردی را برگزینید، نیازی نیست که در تمام متن به دنبال این واژه بگردید و تک به تک آن را تغییر دهید، با استفاده از glossaries با یک بار تغییر کل واژههای درون متن به معادل جدید تبدیل خواهد شد.

واژهنامه در زیپرشین
گذری بر مراحل کار با بسته glossaries
برای وارد کردن واژهنامه و فهرست اختصارات توسط بسته glossaries مراحل زیر را باید طی نمود.
- وارد کردن بسته glossaries
- تنظیمات بسته glossaries و نحوه نمایش واژهنامهها و فهرست اختصارات.
- تعریف واژهها و اختصارات.
- استفاده از واژهها و اختصارات تعریف شده در متن اصلی
- چاپ واژهنامه و فهرست اختصارات در مکانی دلخواه در متن اصلی
- اجرای xelatex و xindy برای تولید واژهنامه و فهرست اختصارات.
در استفاده از مواردی که در این نوشتار خواهد آمد، حتما نکات زیر را مدنظر قرار دهید.
- بستههای Latex مورد استفاده شما حتما باید بروز باشد، به خصوص بستههای xepersian، bidi، glossaries و hyperref.
- کدهایی که در این نوشتار آمده است، توسط glossaries نسخه ۴٫۰۶ به بعد پشتیبانی میشود.
- نحوه استفاده ما از بسته glossaries به گونهای است که به موتور xindy نیاز خواهیم داشت. اگر از TexLive استفاده میکنید نباید نگران باشید، چون این موتور به صورت پیشفرض در Texlive قرار دارد.
- برای اطمینان از درست کار کردن ابزارهای مورد نیاز برای بسته glossaries، در صورتی که روند کامپایل بیان شده در بخش نحوه کامپایل را بر روی فایلهای پیوند Glossaries sample اعمال کنید، میبایست خروجی pdf مشتمل بر فهرست اختصارات و واژهنامه بدون رخداد هیچگونه خطایی تولید گردد.
در ادامه هر یک از مراحل یاد شده را شرح خواهیم داد.
وارد کردن بسته glossaries
در گام نخست شما میبایست بسته glossaries را وارد کنید. در کل سه قانون برای ترتیب وارد کردن بستهها وجود دارد که به شرح زیر است.
- بسته xepersian حتما حتما باید آخرین بستهای باشد که فراخوانی میشود. این قانون کاملا کلی است و در هر متنی که شما قصد نوشتن آن را با استفاده از xepersian دارید باید رعایت شود.
- بسته hyperref جزو آخرین بستههایی باید باشد که فراخوانی میشود. این قانون هم کلی است.
- بسته glossaries حتما باید بعد از hyperref فراخوانی شود.
پس خواهیم داشت:
\usepackage{hyperref}
\usepackage[xindy,acronym,nonumberlist=true]{glossaries}
\usepackage{xepersian}
optionsهایی که در فراخوانی بسته glossaries فعال شده است به شرح زیر است.
- xindy: با این option تعیین میکنیم که برای مرتبسازی واژهها و اختصارات از موتور xindy استفاده شود. با استفاده از این موتور Latex میتواند کلمات فارسی را نیز مرتب سازد.
- acronym: با قرار دادن acronym نشان میدهیم که میخواهیم علاوه بر واژهنامه فهرست اختصارات نیز در متن داشته باشیم. لازم به تذکر است که حتی اگر شما نمیخواهید از فهرست اختصارات در متن استفاده کنید، این option را فعال نگهدارید، چون در بخشهای بعدی فرض شده است که در شما میخواهید اختصارات را نیز با همین روش تولید کنید. البته این فرض خللی در کار شما ایجاد نخواهد کرد.
تنظیمات بسته glossaries
نکته: شما میتوانید از خواندن این بخش صرفنظر کنید. فقط کافی است که تمامی دستوراتی که در فایل قرار داده شده در پیوند glossaries sample قبل از \begin{document} تعریف شده است را در فایل خود وارد کنید. در صورتیکه نحوه نمایش فعلی مناسب است، نیازی نیست خود را درگیر جزئیات بیان شده در این بخش بکنید.
در این مرحله میخواهیم نحوه نمایش واژهنامهها، رفتاری که با واژهها و اختصارات در متن اصلی داریم را تعریف کنیم. دقت کنید که بسته glossaries برای تمامی موارد یاد شده پیشفرضهایی دارد، اما برخی از این پیشفرضها مطابق زبان فارسی نیست که ما سعی میکنیم آنها را مناسب برای یک نوشتار فارسی بکنیم. این بحث را در چند زیربخش دنبال میکنیم.
من با این فرض جلو میروم که شما میخواهید واژههای خود را در دو واژهنامه فارسی به انگلیسی و انگلیسی به فارسی قرار دهید. از سوی دیگر یک فهرست اختصارات نیز میخواهید داشته باشید. به عبارت دیگر شما در کل سه نوع glossary میخواهید توسط بسته glossaries ایجاد کنید. در ابتدا باید برای هر یک از این دو نوع glossary فارسی به انگلیسی و انگلیسی به فارسی یاد شده، نامی انتخاب کنید، اجازه بدهید این نامها را به صورت زیر انتخاب کنیم.
- english نامی که برای واژهنامه انگلیسی به فارسی انتخاب میکنیم.
- persian نامی که برای واژهنامه فارسی به انگلیسی انتخاب میکنیم.
تغییر نحوه نمایش فهرست اختصارات و واژهنامهها
در گام نخست، ما باید استایل هر یک از glossaryهای سهگانه را تعیین کنیم. باز هم تاکید میکنم که اگر شما این کار را نکنید بسته glossaries از پیشفرضهای خود استفاده میکند. به منظور تعریف استایل glossary از دستور newglossarystyle میبایست استفاده کنیم. این دستور شامل بازنویسی برخی از فرامین بسته glossaries به منظور تغییر شکل glossary میشود. بدین منظور سه استایل به نامهای myFaToEn برای استفاده در glossary نوع persian، استایل myEntoFa برای استفاده در glossary نوع english و استایل myAbbrlist برای استفاده برای فهرست اختصارات تعریف میکنیم. به عنوان مثال استایل به صورت زیر تعریف میشود.
%% تعریف استایل برای واژه نامه فارسی به انگلیسی،
\newglossarystyle{myFaToEn}{%
\renewenvironment{theglossary}{}{}
\renewcommand*{\glsgroupskip}{\vskip 10mm}
\renewcommand*{\glsgroupheading}[1]{\subsection*{\glsgetgrouptitle{##1}}}
\renewcommand*{\glossentry}[2]{\noindent\glsentryname{##1}\dotfill\space \glsentrytext{##1}
}
}
%% تعریف استایل برای واژه نامه انگلیسی به فارسی،
\newglossarystyle{myEntoFa}{%
\renewenvironment{theglossary}{}{}
\renewcommand*{\glsgroupskip}{\vskip 10mm}
\renewcommand*{\glsgroupheading}[1]{\begin{LTR} \subsection*{\glsgetgrouptitle{##1}} \end{LTR}}
\renewcommand*{\glossentry}[2]{\noindent\glsentrytext{##1}\dotfill\space \glsentryname{##1}
}
}
%%% تعیین استایل برای فهرست اختصارات
\newglossarystyle{myAbbrlist}{%
\renewenvironment{theglossary}{}{}
\renewcommand*{\glsgroupskip}{\vskip 10mm}
\renewcommand*{\glsgroupheading}[1]{\begin{LTR} \subsection*{\glsgetgrouptitle{##1}} \end{LTR}}
\renewcommand*{\glossentry}[2]{\noindent\Glsentrylong{##1}\dotfill\space \glsentrytext{##1}
}
\renewcommand*{\acronymname}{فهرست اختصارات}
}
نمایی از استایلهای یاد شده در شکلهای زیر نشان داده شده است.
-

- واژهنامه انگلیسی به فارسی

-

- واژهنامه فارسی به انگلیسی

-
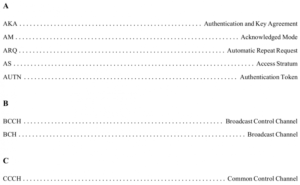
- فهرست اختصارات
برای دستیابی به تعریف دو استایل دیگر به لینک قرار داده شده در قسمت قبل مراجعه کنید.
همانطور که مشاهده میکنید دستوراتی که در هر استایل بکار رفته است مشابه یکدیگر هستند. در مورد این دستورات میتوانید مطالب بیشتری را در راهنمای بسته glossaries بخوانید. اما فقط یکسری نکات کلی:
- با تعریف دوباره دستور glsgroupheading، اینگونه تنظیم میشود که کلمات و اختصارات در گروههایی با سرگروهی حرف ابتدایی واژه و یا اختصار دستهبندی میشوند.
- در مورد واژهنامه انگلیسی به فارسی و فهرست اختصارات به دلیل اینکه سرگروهها حروف انگلیسی هستند آنها را در یک محیط LTR قرار دادیم، تا از سمت چپ نوشته شوند.
- glsgroupskip تعیین میکند که بعد از هر گروه از واژگان یا اختصارات چه عملیاتی انجام شود. برای مثال در استایلهای ذکر شده، فقط تنظیم شده است که یک فاصله بین دو گروه وجود داشته باشد. این کار با \vskip 10mm انجام میشود.
تولید فایلهای موقت
در ادامه تنظیمات، دو دستور زیر را وارد میکنیم.
\newglossary[glg]{english}{gls}{glo}{واژهنامه انگلیسی به فارسی}
\newglossary[blg]{persian}{bls}{blo}{واژهنامه فارسی به انگلیسی}
برای اجرا xindy بر روی فایل .tex و تولید واژهنامهها و فهرست اختصارات و … یکسری فایل تعریف شده است. Latex دادههای مربوط به واژه نامهها و .. را در این فایلها نگهداری میکند. برای مثال برای glossary از نوع english، دو فایل با پسوندهای gls و glo تعریف شده است. هنگامی که شما واژههای خود را در متن اصلی فراخوانی میکنید، دو فایل هم نام با فایل اصلی tex اما با پسوند glo و gls تولید میشود. در مرحلهٔ بعدی (در بخشهای بعدی در مورد این مرحله به طور کامل توضیح خواهیم داد)، xindy بر روی این دو فایل اجرا میشود. این دو فایل در برگیرنده اطلاعاتی در مورد واژه مورد استفاده است. xindy با استفاده از این اطلاعات واژهها را بر اساس حروف الفبا مرتب نموده و برای قرار گیری در فهرست واژگان آماده میسازد، xindy اطلاعات حاصله را در فایلی با پسوند glg ذخیره میسازد.
برای glossary دیگر یعنی persian نیز سه فایل با پسوندهای مختلف تعریف شده است. برای اختصارات نیز سه فایل با پسوندهای acr، acn و alg که به صورت پیش فرض توسط بسته glossaries تخصیص می یابد، و شما لازم نیست آنها را تخصیص دهید.
اولین فراخوانی واژه
در بخشهای بعدی خواهیم گفت که در متن اصلی شما میتوانید با دستورات gls و glspl واژهها و اختصارات خود را فراخوانی کنید. بر طبق استاندارد میخواهیم اولین باری که واژه فراخوانی میشود به صورت خودکار معادل آن پاورقی بخورد. خوشبختانه بسته glossaries از این قابلیت پشتیبانی میکند. برای فعالسازی این قابلیت دو گروه دستور زیر را میبایست در قسمت تنظیمات وارد کنیم.
\defglsentryfmt[english]{\glsgenentryfmt\ifglsused{\glslabel}{}{\LTRfootnote{\glsentryname{\glslabel}}}}
\defglsentryfmt[acronym]{\glsentryname{\glslabel}\ifglsused{\glslabel}{}{\LTRfootnote{\glsentrydesc{\glslabel}}}}
همانطور که مشاهده میکنید در این دو دستور بیان شده است که اگر شما از دستورات gls و glspl در متن استفاده کنید، در اولین بار استفاده به صورت خودکار معادل آن پاورقی بخورد. دقت کنید که با استفاده از این دو دستور میتوانید هر کار دیگری که میخواهید در اولین فراخوانی یک واژه و یا اختصار انجام دهید.
بازتعریف محیط printglossary و تعریف محیط printabbreviation
حال وقت آن رسیده است که نحوه نمایش فهرست واژگان و اختصارات را تنظیم نماییم. در این قسممت محیط استاندارد printglossary را بازتعریف میکنیم. هدف از این بازتعریف این است که هر دو واژهنامه با یک دستور و با استایل مشخص وارد شوند. در ضمن محیطی نیز به عنوان printabbreviation برای تولید فهرست اختصارات تعریف میکنیم. در ضمن هر دو محیط یادشده را به فهرست مطالب و قسمت bookmarkها اضافه میکنیم.
\newcommand{\printabbreviation}{
\cleardoublepage
\phantomsection
\addcontentsline{toc}{chapter}{فهرست اختصارات}
\setglossarystyle{myAbbrlist}
\begin{LTR}
\Oldprintglossary[type=acronym]
\end{LTR}
\clearpage
\baselineskip = \baselineskipVar
}%
\renewcommand{\printglossary}{
\clearpage
\phantomsection
\twocolumn{}
\addcontentsline{toc}{chapter}{واژه نامه انگلیسی به فارسی}
\setglossarystyle{myEntoFa}
\Oldprintglossary[type=english]
\clearpage
\phantomsection
\addcontentsline{toc}{chapter}{واژه نامه فارسی به انگلیسی}
\setglossarystyle{myFaToEn}
\Oldprintglossary[type=persian]
\onecolumn{}
\baselineskip = \baselineskipVar
}%
و اما چند نکته در مورد کدهای فوق:
- همانطور که در کدهای فوق قابل مشاهده است، سه نوع glossary با استایل های مختلف وارد شده است.
- glossary از نوع acronym با استایل myAbbrlist برای فهرست اختصارات
- glossary از نوع english با استایل myEntoFa برای واژهنامه انگلیسی به فارسی
- glossary از نوع persian با استایل myFaToEn برای واژهنامه فارسی به انگلیسی
- اگر دقت کنید برای فهرست واژگان از دستور twocolumn استفاده شده که واژهنامهها به صورت دو ستونی چاپ شود، اما فهرست اختصارات به صورت تک ستونی.
- با دستور addcontentsline فهرست واژگان و اختصارات را به فهرست مطالب اضافه میکنیم.
فعال سازی
برای فعالسازی قرار دادن واژگان دستور زیر را قبل از \begin{document} در فایل خود وارد کنید.
\makeglossaries
تعریف واژهها و اختصارات
در این مرحله باید واژهها و اختصارات را تعریف کنیم. دقت کنید که واژهها و اختصاراتی که در این قسمت تعریف میکنید در واژهنامه و متن وارد نمیشود مگر آنکه از آن استفاده کنید. واژهها و اختصارات را میتوانید در فایلهای جداگانه تعریف کنید و ان را با دستور input وارد کنید. به عنوان مثال سه واژه به صورت زیر تعریف میکنیم.
\newword{RandomVariable}{Random Variable}
{متغیر تصادفی}{متغیرهای تصادفی}
\newword{Action}{Action}
{کنش}{کنشها}
\newword{Optimization}{Optimization}{بهینهسازی}{}
در واقع هر واژه با دستور newword تعریف می شود. این دستور چهار آرگومان به خود میگیرد.
\newword{arg1}{arg2}{arg3}{arg4}
این چهار آرگومان به صورت زیر تعریف میشود.
- arg1: هر واژه یک برچسب یکتا باید برای خود داشته باشد. تمامی ارجاعات به واژه با استفاده از این برچسب انجام میپذیرد.
- arg2: آرگومان دوم تعیین کننده معادل انگلیسی هر واژه است.
- arg3: آرگومان سوم تعیینکننده معادل فارسی کلمه مورد نظر است.
- arg4: این آرگومان حالت جمع arg3 است.
برای مثال کلمه Network معادل فارسیش میشود، شبکه و حالت جمع آن شبکههااست. و یا کلمه Action معادل فارسیش میشود کنش و حالت جمع آن می شود کنشها. لازم به ذکر است که اگر کلمهای حالت جمع ندارد میتوانید arg4 را خالی بگذارید.
برای تعریف یک اختصار نیز به صورت زیر عمل میکنیم. به عنوان مثال در ادامه دو اختصار را تعریف میکنیم.
\newacronym{MOMT}{MO-MT}{Mobile Originated - Mobile Terminated}
\newacronym{MS}{MS}{Mobile Station}
یک اختصار با دستور
\newacronym{arg1}{arg2}{arg3}
- arg1: برچسبی اختیاری برای اختصاری که میخواهید آن را تعریف کنید.
- arg2: معادل name اختصار و یا حالت خلاصه شده آن.
- arg3: حالت بازشده اختصار مورد نظر است.
نکات
- شما میتوانید به عنوان مثال واژهها و اختصارات را در یک فایل جدا تعریف کنید و سپس در قبل از \begin{document} آن را وارد کنید. برای مثال فرض کنید که در فایل mygloss.tex واژهها تعریف شده است، اکنون کافی است که:
\documentclass{report}
......................
......................
\input{mygloss}
\begin{document}
- دقت کنید که برچسب اختصارات و واژگان به هیچ وجه نباید یکسان باشد.
استفاده از واژهها و اختصارات
در بسته glossaries روشهای مختلفی برای فراخوانی واژهها و اختصارات قرار داده شده است. در ادامه به صورت مختصر این مطلب را توضیح میدهیم. دقت کنید که آرگومان ورودی تمامی دستورات یاد شده، label واژه و یا اختصار تعریف شده است.
gls
با این دستور معادل فارسی واژه یاد شده در مکانی که این دستور را قرار دادهاید وارد میشود. مثال فرض کنید در قسمت واژهنامه، واژهای به صورت زیر تعریف میکنیم.
\newword{Action}{Action}
{کنش}{کنشها}
اکنون اگر در فایل tex خود بنویسیم «یک ربات در مجموع تعدادی \gls{Action} میتواند انجام دهد»، خروجی pdf به صورت «یک ربات در مجموع تعدادی کنش میتواند انجام دهد» خواهد بود. در ضمن اگر این اولین باری است که از این واژه استفاده میکنیم، به طور خودکار معادل انگلیسی واژه استفاده شده یعنی کنش که Action است، در پاورقی وارد میشود.
برای اختصارات، نیز فرض کنید اختصاری به صورت زیر تعریف کردهایم.
\newacronym{DFT-My}{DFT}{Discrete Fourier Transform}
اکنون در متن خود برای وارد کردن DFT میتوانید از دستور gls استفاده کنید:
یکی از تبدیلات مهم \gls{DFT-My} است.
آنچه که شما در خروجی pdf خواهید دید به صورت زیر خواهد شد:
یکی از تبدیلات مهم DFT است.
در ضمن اگر این اولین باری است که از این اختصار استفاده میکنیم، به طور خودکار حالت بازشده آن یعنی Discrete Fourier Transform، در پاورقی وارد میشود.
glspl
با استفاده از این دستور میتوانید حالت جمع یک واژه را در متن وارد کنید. بار دیگر فرض کنید که واژهای به صورت زیر در قسمت واژگان تعریف کردهاید.
\newword{RandomVariable}{Random Variable}
{متغیر تصادفی}{متغیرهای تصادفی}
اکنون فرض کنید که در متن فایل tex خود عبارت زیر را نوشتهاید.
مجموع \glspl{RandomVariable} را میتوان به صورت…
خروجی فایل pdf چیزی شبیه به صورت زیر خواهد شد.
مجموع متغیرهای تصادفی را میتوان به صورت…
همانطور که مشاهده میکنید حالت جمع واژه RandomVariable قرار داده شده است. در ضمن اگر این کلمه برای اولین بار مورد استفاده قرار گرفته است، معادل انگلیسی حالت مقرد آن یعنی Random Variable در پاورقی وارد میشود.
*glspl و *gls
این دستورات به مانند glspl و gls عمل میکند. یعنی حالت مفرد یا جمع واژه را در متن میگذارد، واژه را در واژهنامهها وارد میکند. اما اگر اولین مرتبهای است که واژه فراخوانی میشود آن را پاورقی نمیزند. به عنوان مثال متن زیر را در نظر بگیرید.
یک ربات در مجموع تعدادی \glspl*{Action} میتواند انجام دهد. اما \glspl{Action} یک ربات را میتوان…
در خروجی pdf، در هر دو حالت قسمت حالت جمع واژه با برچسب Action قرار میگیرد. اما با اینکه در اولین جمله اولینباری است که کلمه Action آمده است، این کلمه پاورقی نمیخورد. و اولین بار فراخوانی واژه Action در جمله دوم در نظر گرفته میشود و همان جا نیز پاورقی ایجاد خواهد شد.
اما سوال اینجا است که این حالت * به چه کار خواهد آمد؟ فرض کنید که شما میخواهید در caption یک جدول یا شکل یک واژه را بکار ببرید. مثلا فرض کنید:
\begin{figure}
\includegraphics{...................}
\caption{
این مثالی از یک \gls{Action} مجاز است.
}
\label{fig:sample}
\end{figure}
همانطور که میدانید caption ها اشکال در فهرست اشکال جمعآوری میشوند، و به احتمال زیاد اولین جایی که واژه Action بکار میرود در caption ها است که در فهرست اشکال آورده شده است. پرواضح است که ما نمیخواهیم در فهرست اشکال پاورقی داشته باشیم. پس بهتر است که در caption جداول و اشکال از حالت * دستورات استفاده کنیم. یعنی:
\begin{figure}
\includegraphics{...................}
\caption{
این مثالی از یک \gls*{Action} مجاز است.
}
\label{fig:sample}
\end{figure}
glsentrytext
این دستور به مانند gls است. با این تفاوت که فقط در متن قسمت text اختصار یا واژه مورد نظر وارد میشود، و واژه مورد نظر نه پاورقی میخورد و نه در واژهنامهها وارد میشود. برای واژه و اختصار زیر را در نظر بگیرید.
\newword{Optimization}{Optimization}{بهینهسازی}{}
\newacronym{DFT}{DFT}{Discrete Fourier Transform}
اکنون اگر در متن خود بنویسید:
میتوانیم با \glsentrytext{Optimization} تبدیل \glsentrytext{DFT} را…
شما در خروجی pdf عبارت زیر را مشاهده خواهید کرد.
میتوانیم با بهینهسازی تبدیل DFT را…
اما واژه Optimization و اختصار DFT اگر در این جا حتی اولین باری باشد که بکار رفته باشد، دیگر پاورقی نخواهد خورد، در ضمن این واژه و اختصار وارد واژهنامه و فهرست اختصارات نیز نخواهد شد.
glsentryplural
این دستور به مانند glspl است. با این تفاوت که فقط در متن قسمت جمع واژه مورد نظر وارد میشود، و واژه مورد نظر نه پاورقی میخورد و نه در واژهنامهها وارد میشود.
glsuseri
اگر از این دستور استفاده کنید، واژه و یا اختصار در متن نمی آید اما در واژه نامه و یا فهرست اختصارات وارد میشود.
نکات
در وارد کردن واژهها و اختصارات به نکات زیر دقت کنید.
- در قسمت caption جدول و شکل از gls و glspl استفاده نکنید. به جای آن از *glspl و *gls استفاده کنید. چرا که اگر از gls و glspl در قسمت captionاستفاده کنید، و فهرست تصاویر و جداول را وارد کنید، همواره اولین جایی که واژه مورد نظر بکار میرود، در ابتدای نوشتار در فهرست جداول و اشکال است، و شما مشاهده میکنید که در این فهرستها پاورقی ظاهر میشود که کار درستی نیست. شکل روبهرو را مشاهده کنید.
- اتفاق یاد شده برای فهرست مطالب نیز رخ میدهد. پس در عنوان chapter، section، subsection و subsubsection به هیچوجه از gls و glspl استفاده نکنید. در ضمن به دلیل مشکلی که در قسمت bookmark بسته hyperref با glossaries دارد، از *gls و *glspl نیز نمیتوانید استفاده کنید. در صورت استفاده bookmarkها به درستی نمایش داده نمیشوند. پس تنها مجبور هستید که از glsentryplural و glsentrytext استفاده کنید.
- اگر بخواهیم مثلا یک کلمه در واژه نامه را Indexکنیم، مثلا بنویسیم، \index{\glspl{Water}}، این دستور index درست عمل نمیکند. نویسنده بسته glossaries در این باره این طور گفته است:
If you inspect the .idx file you will see that it contains the following: \indexentry{\glsentryplural{StrictlyStable}|hyperpage}{۱} \index doesn’t expand its argument when writing to the .idx file and since xindy doesn’t understand (La)TeX commands the index won’t be correctly sorted. This is a feature of \index and is not connected with glossaries. You could try something like \expandafter\index\expandafter{\glsentryplural{StrictlyStable}}
پس برای وارد کردن واژهها در نمایه به جای دستور index باید دستورات زیر را به ترتیب برای gls و glspl استفاده نمود.
\expandafter\index\expandafter{\glsentryname{.......}}
\expandafter\index\expandafter{\glsentryplural{.......}}
چاپ واژهنامه و فهرست اختصارات
با توجه به بازتعریف محیطهای وارد کردن واژهنامه و فهرست اختصارات در قسمت تنظیمات، در این قسمت کافی است هر کجا که میخواهید دو واژهنامه فارسی به انگلیسی و انگلیسی به فارسی وارد شود، دستور \printglossary را وارد کنید. برای فهرست اختصارات نیز در مکان دلخواه دستور \printabbreviation را وارد کنید.
- بر طبق استاندارد بهتر است واژهنامهها بعد از قسمت مراجع و قبل از نمایه وارد شود.
- فهرست اختصارات بهتر است بعد از فهرست جداول و اشکال در ابتدای متن وارد شود.
نحوه کامپایل
بعد از طی مراحل قبلی، به آخرین مرحله میرسیم. در آخرین مرحله میبایست فایل خود را کامپایل کنیم، و موتور xindy را بر روی آن اجرا کنیم. بدین منظور گامهای یاد شده در ادامه را انجام دهید.
گام اول: ابتدا یک بار فایل خود را با xelatex کامپایل کنید. اگر در editor مورد استفاده شما، برای کامپایل xelatex تنظیم شده است، کافی است گزینه quick build را اجرا کنید. نکته: در صورتی که از texmaker یا texstudio و یا دیگر ویرایشگرها استفاده میکنید، تنظیم پیشفرض pdflatex است نه xelatex. برای xelatex کردن تنظیم پیشفرض اگر به عنوان مثال از Texstudio استفاده می کنید، از منوی option گزینه configure texstudio را انتخاب کنید، و در پنجره ای که باز می شود از قسمت Build و گزینه Default compiler کامپایلر را به xelatex تغییر دهید.
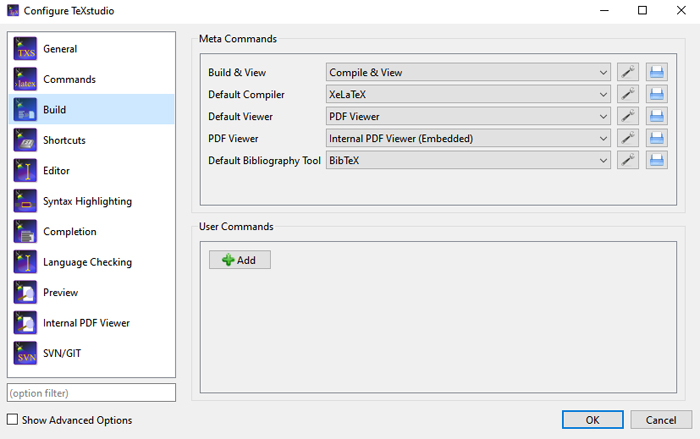
گام دوم: در این مرحله باید سه دستور زیر را بر روی فایل اصلی اعمال کنید.
xindy -L persian-variant1 -C utf8 -I xindy -M %.xdy -t %.glg -o %.gls %.glo xindy -L persian-variant1 -C utf8 -I xindy -M %.xdy -t %.blg -o %.bls %.blo xindy -L english -C utf8 -I xindy -M %.xdy -t %.alg -o %.acr %.acn
برای اجرای این سه دستور کافی است که این سه دستور را در ویرایشگر خود تعریف کنید. برای مثال در ویرایشگر Texstudio باید به صورت زیر عمل کنید.
- از منوی option گزینه configure Texstudio را انتخاب کنید.
- به قسمت Build بروید.
- در قسمت user command یک دستور با یک نام دلخواه دستوری به صورت زیر را وارد کنید.
xindy -L persian-variant1 -C utf8 -I xindy -M %.xdy -t %.glg -o %.gls %.glo | xindy -L persian-variant1 -C utf8 -I xindy -M %.xdy -t %.blg -o %.bls %.blo | xindy -L english -C utf8 -I xindy -M %.xdy -t %.alg -o %.acr %.acn
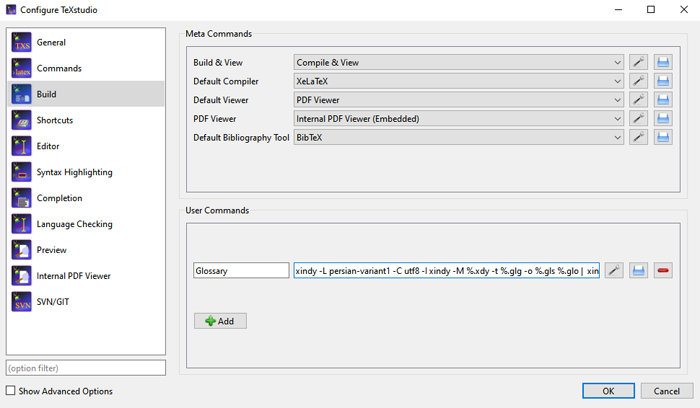
- پس تایید برای اجرا به منوی tools و قسمت users رفته و در آن جا بر روی دستوری که تعریف کردید کلیک کنید.
- با کلیک بر روی این دستور هر سه دستور باد شده اجرا میگردند.
گام سوم: در مرحله کامپایل بعدی، دو بار دیگر دستور quick build را اجرا کنید. اکنون در فایل خروجی pdf واژهها و اختصارات به صورت مرتب شده در واژهنامهها و فهرست اختصارات قرار میگیرد.
نویسنده: ابوالفضل دیانت